robots.txt 생성기 & 검증기
검색엔진 크롤러의 접근을 제어하는 robots.txt 파일을 생성하거나 검증합니다.
프리셋
User-Agent #1
Sitemap (선택)
미리보기
# robots.txt generated by SEO SOVISS # https://seo.soviss.com/tools/robots-txt User-agent: * Allow: /
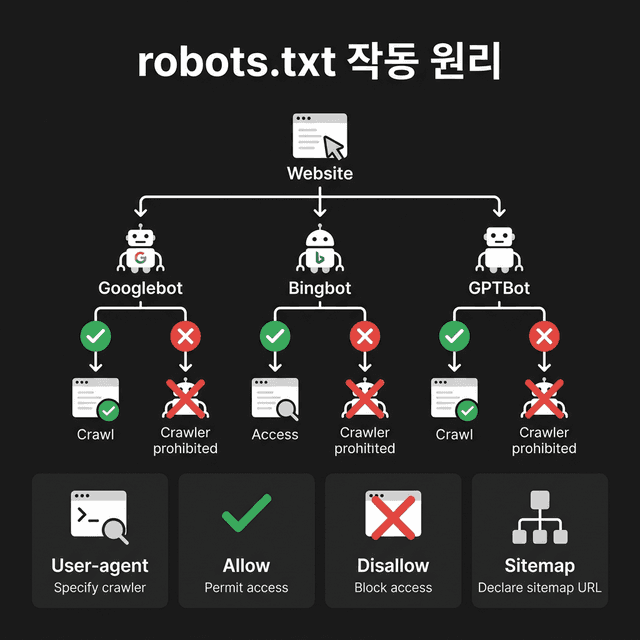
robots.txt 자주 묻는 질문
Q. robots.txt 파일이 왜 필요한가요?
robots.txt는 검색엔진 크롤러에게 사이트의 어떤 페이지를 크롤링해도 되는지 알려주는 파일입니다. 관리자 페이지, API 엔드포인트, 중복 콘텐츠 등을 차단하여 크롤링 예산(Crawl Budget)을 효율적으로 관리할 수 있습니다. 모든 검색엔진은 사이트 방문 시 가장 먼저 이 파일을 확인합니다.
Q. Googlebot을 차단하면 검색 순위에 영향이 있나요?
네, Googlebot을 Disallow로 차단하면 해당 경로의 페이지는 Google 검색 결과에 나타나지 않습니다. 단, 이미 색인된 페이지는 robots.txt 차단만으로 제거되지 않으며, noindex 메타 태그나 Google Search Console에서 별도로 제거 요청해야 합니다.
Q. AI 크롤러(GPTBot, ClaudeBot 등)는 어떻게 관리하나요?
GPTBot(OpenAI), ClaudeBot(Anthropic), Google-Extended(Google AI) 등 AI 크롤러는 각각 고유한 User-Agent를 사용합니다. robots.txt에서 이들을 개별적으로 차단하거나 허용할 수 있습니다. AI 학습용 크롤링만 차단하면서 검색엔진 크롤링은 허용하려면, AI 봇만 별도로 Disallow 설정하세요.